Part 7 ResNet
1 残差块与 ResNet 模型
让我们重新考虑一下训练模型是为了得到什么。我们输入一个,经过一系列训练后得到一个理想映射,我们期望理想映射的输出能较好地表示我们的输入。换句话说,是对的拟合。
事实上是一定不可能完美拟合的,我们称二者的差值为残差映射。残差越小,则证明拟合效果越好。
ResNet 采用了这种想法:训练过程可以不以为目标,而是以残差映射为目标。当我们训练得到一个较好的时(即),只需要再加上原始输入,就能得到我们想要的理想映射,即。
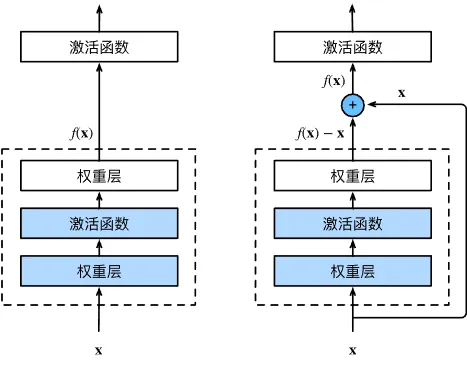
如图所示,ResNet 的基础结构称为残差块。
ResNet 每个残差块中有两个相同通道的 3×3 卷积层,每个卷积层后接一个批量规范化层和 ReLU 激活函数。在残差块外,我们直接将输入加在最后的 ReLU 激活函数之前。如果想要改变通道数,就需要引入额外的一个 1×1 卷积层。
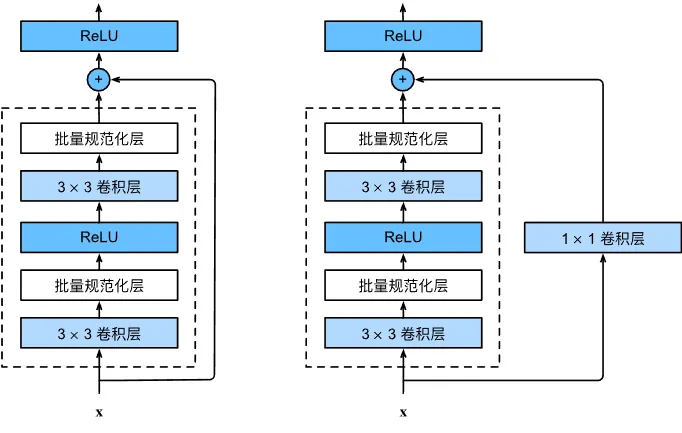
批量规范化层
在训练深层神经网络时,中间层激活的分布可能会不断变化(即所谓的“内部协变量偏移”),这会导致训练不稳定、收敛缓慢,甚至梯度爆炸或消失。
批量规范化在每次迭代中,首先基于当前小批量规范化输入,然后应用比例系数和比例偏移,使其均值接近 0、方差接近 1。
其中: 和 分别是当前小批量的均值与标准差; 和 是可学习的缩放系数与偏移量; 表示逐元素乘法。
跳过繁琐的数学推理,这里直接给出批量规范化层的 PyTorch 实现。
nn.BatchNorm2d(16) # 具有 16 个输出通道的批量规范化层这种规范化通常用于卷积层之后、非线性激活之前。
ResNet 的前两个模块和 GoogLeNet 相似,第一模块是 64 通道的 7×7 卷积层和 3×3 的最大池化层,第二模块是 64 通道的 1×1 卷积层、192 通道的 3×3 卷积层和 3×3 的最大池化层。然后每个模块之后添加批量规范化层。
不同的是后面的残差块。ResNet 使用了 4 个残差块组成的模块。第一个模块的通道数同输入通道数一致,之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
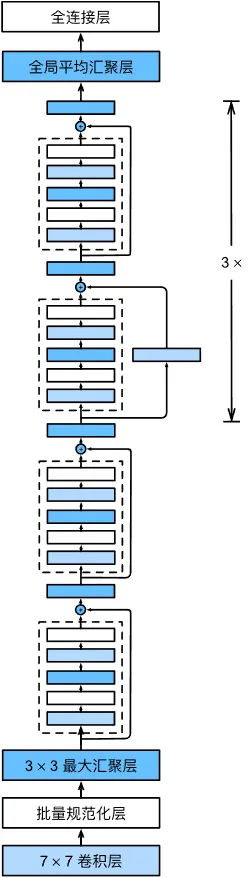
如图所示,每个模块有 4 个卷积层,加上第一个 7×7 卷积层和最后一个全连接层,共有 18 层。因此这个模型被称为 ResNet-18。
2 ResNet-18 的 PyTorch 实现
我们先来设计残差块:
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)参数use_1x1conv是为了改变通道数。
def resnet_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True, strides=2)
)
else:
blk.append(Residual(num_channels, num_channels))
return blk然后堆叠各模块:
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(
b1,
b2,
b3,
b4,
b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 10),
)学习率调整为 0.05,其他训练过程不变。