Part 3 单阶段检测器 SSD
单阶段检测器跳过了候选区域提取过程,直接从图像特征中回归物体的类别与位置,兼顾速度与精度,是当前主流的实时目标检测方案。
代表性的单阶段检测器有 SSD 和 YOLO 系列模型。这一节主要介绍 SSD。
1 SSD 整体结构
SSD 主要由基础网络组成,其后是几个多尺度特征块。基础网络用于从输入图像中提取特征,原始论文中使用的是 VGG 的一部分作为基础网络,现在也常用 ResNet 代替。
我们也可以设计自己的基础网络,使其输出较大尺寸的特征图。这样根据大尺寸特征图生成的锚框数量较多,就可以用来检测较小的目标。接下来的每个多尺度特征块将上一层输出的特征图缩小,同时使特征图中每个单元在输入图像上的感受野更广阔。
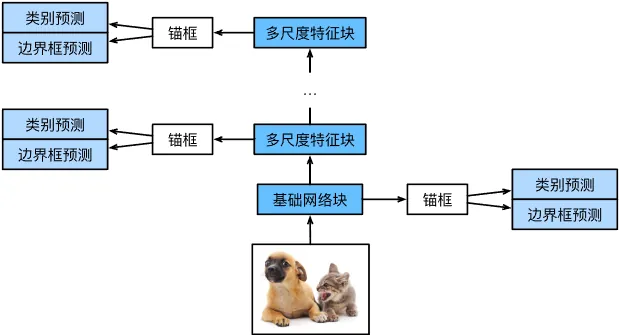
根据上图可以知道,接近 SSD 顶部的多尺度特征图较小,但具有较大的感受野,适合检测大而少的物体,而底部的大尺寸特征图感受野小,适合检测小而多的物体。
1.1 类别预测层
图像的像素数量较大,直接使用全连接层作为输出会导致模型参数过多。因此 SSD 和 NiN 的做法一样,使用卷积层的通道来输出预测类别。
具体而言,类别预测层使用一个保持输入尺寸的卷积层,使得输入和输出在特征图的空间坐标一一对应。考虑输出和输入的同一坐标,输出特征图上坐标的通道里包含了以输入特征图坐标为中心生成的所有锚框的类别预测。因此输出通道数为,其中为每个单元中心的锚框数量,为目标类别数量(加上背景为一类,共有类)。在所有的输出通道中,索引为的通道代表索引为的锚框对类别索引为的预测。
def cls_predictor(num_inputs, num_anchors, num_classes):
return nn.Conv2d(
num_inputs, num_anchors * (num_classes + 1), kernel_size=3, padding=1
)1.2 边界框预测层
边界框预测层的设计和类别预测层类似。不同的是,这里需要为每个锚框预测 4 个偏移量,而非个类别。
def bbox_predictor(num_inputs, num_anchors):
return nn.Conv2d(num_inputs, num_anchors * 4, kernel_size=3, padding=1)1.3 多尺度预测块的连接
SSD 使用多尺度特征图来生成锚框并预测其类别和偏移量。在不同的尺度下,特征图的形状或以同一单元为中心的锚框的数量可能会有所不同。因此,不同尺度下预测输出的形状可能会有所不同。
类别预测输出的形状为(批量大小, 通道数, 高度, 宽度)。除了批量大小这一维度外,通道数、高度、宽度这三个维度都具有不同的尺寸。为了将不同的预测输出连接起来提高计算效率,我们把通道数移动到最后一维,然后转换成二维张量(批量大小, 高度×宽度×通道数),方便在第一维度上进行连接。
def flatten_pred(pred):
return torch.flatten(pred.permute(0, 2, 3, 1), start_dim=1)
def concat_preds(preds):
return torch.cat([flatten_pred(p) for p in preds], dim=1)1.4 下采样块
为了在多个尺度下预测目标,SSD 每个多尺度特征块将上一层输出的特征图缩小。我们这里将其减半。每个下采样块由两个填充为 1 的 3×3 卷积层和步幅为 2 的 2×2 最大池化层组成。
填充为 1 的 3×3 卷积层不会改变特征图的尺寸,但是 2×2 最大池化层将输入特征图的宽高减少一半。对于输出特征图,其每个单元都在输入上有一个 6×6 的感受野。
感受野的计算
感受野可以逐层计算,每层感受野的大小由以下公式决定:
其中, 为上一层的感受野大小,为卷积核大小,为步幅。
def down_sample_blk(in_channels, out_channels):
blk = []
for _ in range(2):
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.BatchNorm2d(out_channels))
blk.append(nn.ReLU())
in_channels = out_channels
blk.append(nn.MaxPool2d(2))
return nn.Sequential(*blk)1.5 基本网络块
基本网络块用于从图像中抽取特征。为了计算简洁,我们构造一个小的基础网络。该网络串联三个下采样块,并逐步将通道数翻倍。
给定输入图像的形状为 256×256,此时基本网络块输出特征图的形状为 32×32。
def base_net():
blk = []
num_filters = [3, 16, 32, 64]
for i in range(len(num_filters) - 1):
blk.append(down_sample_blk(num_filters[i], num_filters[i+1]))
return nn.Sequential(*blk)2 定义 SSD 模型
完整的 SSD 由五个模块组成,每个块的特征图既用于生成锚框、又用于预测锚框的类别和偏移量。
五个模块中,第一个是基本网络块,第二到四个是下采样块,最后一个模块使用全局最大池化将高度和宽度降为 1。从技术上讲,第二到五块都是 SSD 的多尺度特征块。
def get_blk(i):
if i == 0:
blk = base_net()
elif i == 1:
blk = down_sample_blk(64, 128)
elif i == 4:
blk = nn.AdaptiveMaxPool2d((1, 1))
else:
blk = down_sample_blk(128, 128)
return blk然后我们为每个块定义前向传播。每个块应该输出特征图Y、根据Y生成的锚框和这些锚框的类别和偏移量。
def blk_forward(X, blk, size, ratio, cls_predictor, bbox_predictor):
Y = blk(X)
anchors = multibox_prior(Y, sizes=size, ratios=ratio)
cls_preds = cls_predictor(Y)
bbox_preds = bbox_predictor(Y)
return (Y, anchors, cls_preds, bbox_preds)相关信息
multibox_prior是生成锚框的方法,在这里直接给出:
def multibox_prior(data, sizes, ratios):
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
boxes_per_pixel = (num_sizes + num_ratios - 1)
size_tensor = torch.tensor(sizes, device=device)
ratio_tensor = torch.tensor(ratios, device=device)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的高为1且宽为1,我们选择偏移我们的中心0.5
offset_h, offset_w = 0.5, 0.5
steps_h = 1.0 / in_height # 在y轴上缩放步长
steps_w = 1.0 / in_width # 在x轴上缩放步长
# 生成锚框的所有中心点
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
shift_y, shift_x = shift_y.reshape(-1), shift_x.reshape(-1)
# 生成“boxes_per_pixel”个高和宽,
# 之后用于创建锚框的四角坐标(xmin,xmax,ymin,ymax)
w = torch.cat((size_tensor * torch.sqrt(ratio_tensor[0]),
sizes[0] * torch.sqrt(ratio_tensor[1:])))\
* in_height / in_width # 处理矩形输入
h = torch.cat((size_tensor / torch.sqrt(ratio_tensor[0]),
sizes[0] / torch.sqrt(ratio_tensor[1:])))
# 除以2来获得半高和半宽
anchor_manipulations = torch.stack((-w, -h, w, h)).T.repeat(
in_height * in_width, 1) / 2
# 每个中心点都将有“boxes_per_pixel”个锚框,
# 所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次
out_grid = torch.stack([shift_x, shift_y, shift_x, shift_y],
dim=1).repeat_interleave(boxes_per_pixel, dim=0)
output = out_grid + anchor_manipulations
return output.unsqueeze(0)在前向传播中每个多尺度特征块上,我们通过调用的multibox_prior函数的sizes参数传递两个比例值的列表。
在下面,0.2 和 1.05 之间的区间被均匀分成五个部分,以确定五个模块的在不同尺度下的较小值:0.2、0.37、0.54、0.71 和 0.88。
之后,他们较大的值由、等给出。
sizes = [[0.2, 0.272], [0.37, 0.447], [0.54, 0.619], [0.71, 0.79], [0.88, 0.961]]
ratios = [[1, 2, 0.5]] * 5
num_anchors = len(sizes[0]) + len(ratios[0]) - 1于是我们可以定义 SSD 模型:
class TinySSD(nn.Module):
def __init__(self, num_classes, **kwargs):
super(TinySSD, self).__init__(**kwargs)
self.num_classes = num_classes
idx_to_in_channels = [64, 128, 128, 128, 128]
for i in range(5):
# 即赋值语句self.blk_i=get_blk(i)
setattr(self, f'blk_{i}', get_blk(i))
setattr(self, f'cls_{i}', cls_predictor(idx_to_in_channels[i],
num_anchors, num_classes))
setattr(self, f'bbox_{i}', bbox_predictor(idx_to_in_channels[i],
num_anchors))
def forward(self, X):
anchors, cls_preds, bbox_preds = [None] * 5, [None] * 5, [None] * 5
for i in range(5):
# getattr(self,'blk_%d'%i)即访问self.blk_i
X, anchors[i], cls_preds[i], bbox_preds[i] = blk_forward(
X, getattr(self, f'blk_{i}'), sizes[i], ratios[i],
getattr(self, f'cls_{i}'), getattr(self, f'bbox_{i}'))
anchors = torch.cat(anchors, dim=1)
cls_preds = concat_preds(cls_preds)
cls_preds = cls_preds.reshape(
cls_preds.shape[0], -1, self.num_classes + 1)
bbox_preds = concat_preds(bbox_preds)
return anchors, cls_preds, bbox_preds3 训练 SSD 模型
3.1 读取数据集和初始化
为了方便,我们直接使用 d2l 提供的数据集:
batch_size = 32
train_iter, _ = d2l.load_data_bananas(batch_size)然后初始化网络:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = TinySSD(num_classes=1)3.2 损失函数
目标检测有两种类型的损失:类别损失和锚框偏移量损失。
类别损失可以直接套用之前的图像分类问题中的交叉熵损失函数。而锚框偏移量是一个回归问题,我们可以用平方损失和范数损失,这里我们使用后者,即预测值和真实值之差的绝对值。掩码变量bbox_masks令负类锚框和填充锚框不参与损失的计算。
将两类损失相加,得到最终损失函数。
cls_loss = nn.CrossEntropyLoss(reduction="none")
bbox_loss = nn.L1Loss(reduction="none")
def calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels, bbox_masks):
batch_size, num_classes = cls_preds.shape[0], cls_preds.shape[2]
cls = (
cls_loss(cls_preds.reshape(-1, num_classes), cls_labels.reshape(-1))
.reshape(batch_size, -1)
.mean(dim=1)
)
bbox = bbox_loss(bbox_preds * bbox_masks, bbox_labels * bbox_masks).mean(dim=1)
return cls + bbox3.3 评价函数
我们可以沿用准确率评价分类结果。
由于偏移量使用了范数损失,我们使用平均绝对误差来评价边界框的预测结果。这些预测结果是从生成的锚框及其预测偏移量中获得的。
def cls_eval(cls_preds, cls_labels):
# 由于类别预测结果放在最后一维,argmax需要指定最后一维。
return float(
(cls_preds.argmax(dim=-1).type(cls_labels.dtype) == cls_labels).sum()
)
def bbox_eval(bbox_preds, bbox_labels, bbox_masks):
return float((torch.abs((bbox_labels - bbox_preds) * bbox_masks)).sum())3.4 训练模型
num_epochs = 20
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], legend=['class error', 'bbox mae'])
net = net.to(device)
for epoch in range(num_epochs):
# 训练精确度的和,训练精确度的和中的示例数
# 绝对误差的和,绝对误差的和中的示例数
metric = d2l.Accumulator(4)
net.train()
for features, target in train_iter:
trainer.zero_grad()
X, Y = features.to(device), target.to(device)
# 生成多尺度的锚框,为每个锚框预测类别和偏移量
anchors, cls_preds, bbox_preds = net(X)
# 为每个锚框标注类别和偏移量
bbox_labels, bbox_masks, cls_labels = d2l.multibox_target(anchors, Y)
# 根据类别和偏移量的预测和标注值计算损失函数
l = calc_loss(cls_preds, cls_labels, bbox_preds, bbox_labels,
bbox_masks)
l.mean().backward()
trainer.step()
metric.add(cls_eval(cls_preds, cls_labels), cls_labels.numel(),
bbox_eval(bbox_preds, bbox_labels, bbox_masks),
bbox_labels.numel())
cls_err, bbox_mae = 1 - metric[0] / metric[1], metric[2] / metric[3]
animator.add(epoch + 1, (cls_err, bbox_mae))
print(f'class err {cls_err:.2e}, bbox mae {bbox_mae:.2e}')