Part 1 YOLOv8 结构
从这一节开始,我们将学习 YOLOv8 这一目标检测模型。你可以在 Ultralytics 仓库中找到源代码。
在卷积神经网络中,通常将模型分为两到三个部分:Backbone、Neck 和 Head。
- Backbone(骨干网络)负责从输入图像中提取特征,将图像转化为具有丰富语义信息的特征表示;
- Neck(颈部、连接部)是中间层,用于对来自 Backbone 的特征进行融合,以提升模型的性能;
- Head(任务头)是模型的最后一层,其结构会根据不同的任务而有所不同。例如,在图像分类任务中,我们通常会使用 softmax 分类器作为 Head,而在目标检测任务中,我们则可能会使用边界框回归器和分类器作为 Head。
YOLO 系列模型和 SSD 一样都是单阶段检测器。不同的是,YOLOv8 相对于 SSD 来说更加庞大、复杂。
在正式开始之前,我们先看一下 YOLOv8 的整体结构:
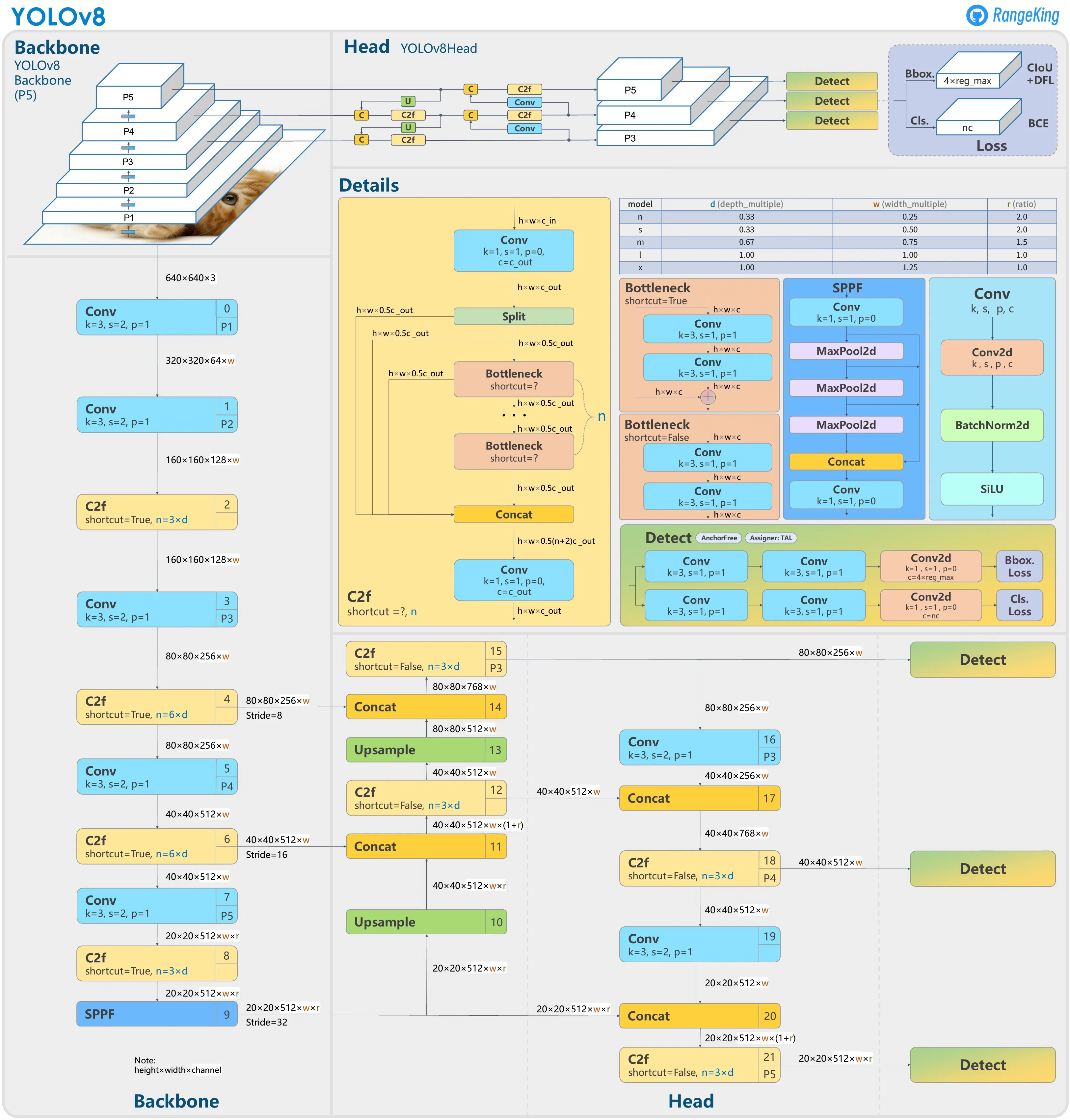
一眼看上去的确很复杂,但是我们仔细观察,发现 YOLOv8 和我们学习过的经典卷积神经网络一样,只是Conv C2f Bottleneck SPPF Detect 等网络组件的堆叠为 Backbone 和 Head 两部分(YOLOv8 没有 Neck)。
图的上部为 YOLOv8 架构的概要图,包括 Backbone 和 Head。
图的中间靠右 Details 部分为主要网络组件的详细架构,以及不同尺寸模型的参数选择。
图左和图下部以分步形式列出了完整的数据流,每个框右上角的数字为层的编号。可以看出第 0 到 9 层为 Backbone,第 10 到 21 层为 Head。
1 主要网络组件
1.1 Conv
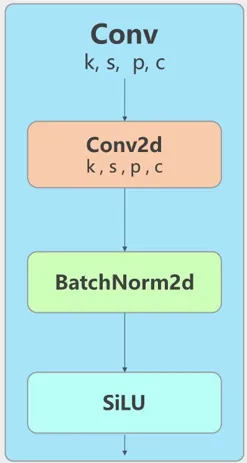
标准卷积操作。先执行二维卷积,然后再进行批量归一化,最后使用 SiLU 激活函数。
你可以在路径 ultralytics/nn/modules/conv.py 找到原始实现Conv。
1.2 Bottleneck
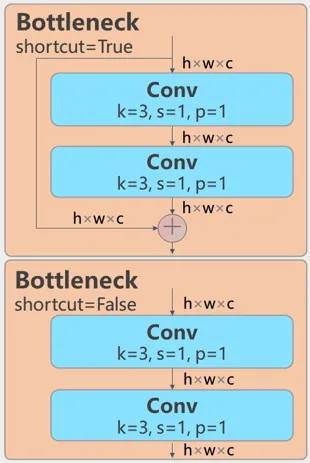
结构非常简单,为两个卷积层,外加一个是否为残差网络的标记shortcut。
你可以在路径 ultralytics/nn/modules/block.py 找到原始实现Bottleneck。
1.3 C2f
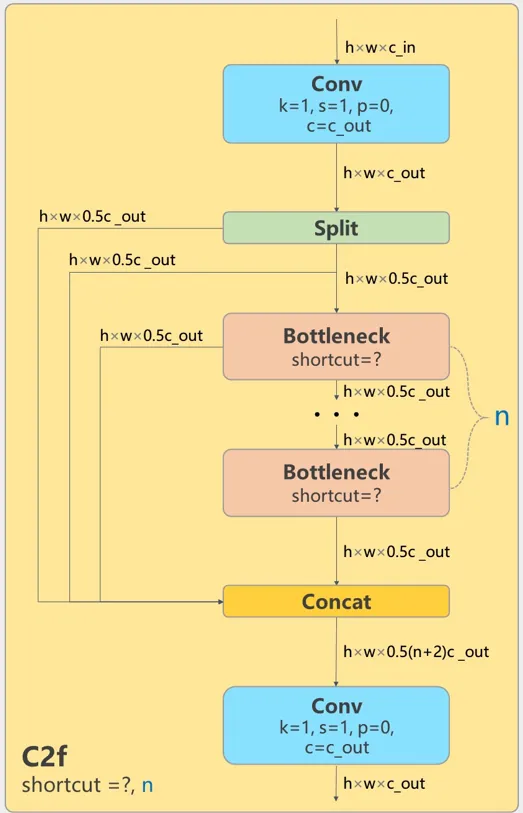
包含一个 1×1 卷积层、两个带shortcut参数的 Bottleneck 层,连接后再做一个 1×1 卷积层。
你可以在路径 ultralytics/nn/modules/block.py 找到原始实现C2f。
1.4 SPPF
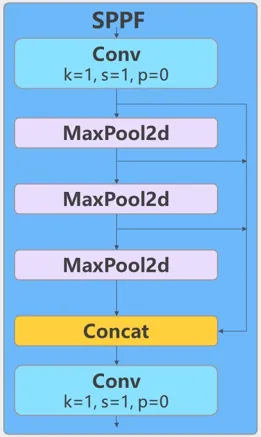
快速空间金字塔池化。通过在特征图上执行不同大小的池化操作,并将结果进行整合,从而得到固定尺寸的输出。这种技术可以有效地处理尺寸变化多样的目标,从而提高了神经网络的泛化能力和鲁棒性。
该部分由一个 1×1 卷积层、三个 5×5 最大池化层连接后,再进行 1×1 卷积。
你可以在路径 ultralytics/nn/modules/block.py 找到原始实现SPPF。
1.5 Detect
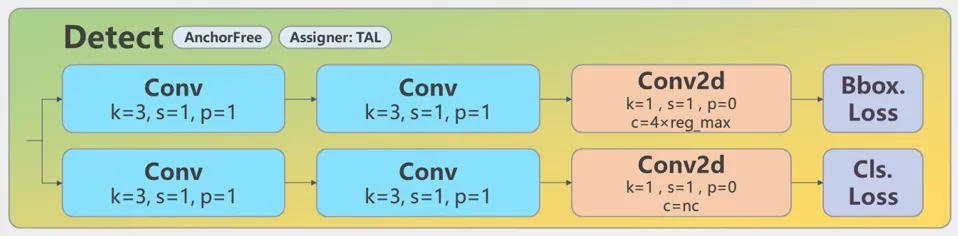
YOLOv8 的检测头。每个检测头包含两个 Conv + Conv + nn.Conv2d 分支,分别预测边界框和分类。
你可以在路径 ultralytics/nn/modules/head.py 找到原始实现Detect。
2 Backbone
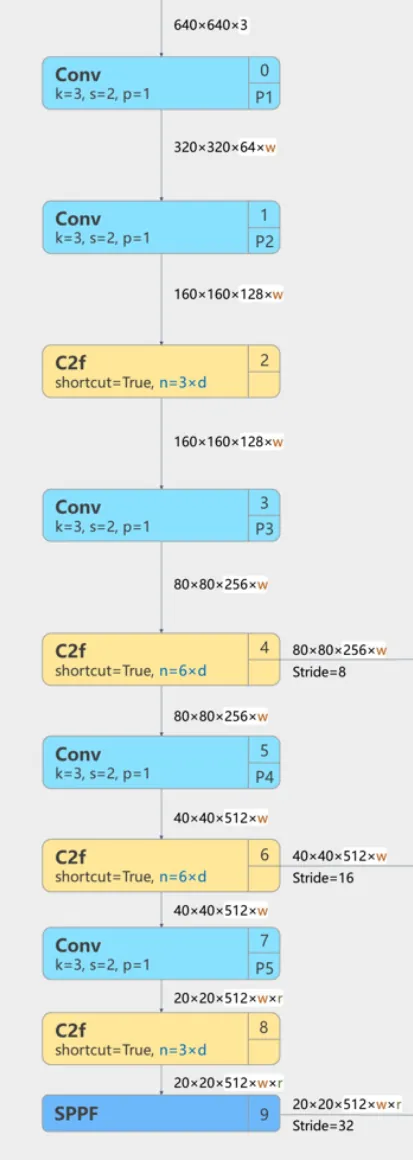
YOLOv8 的 Backbone 见图中左侧第 0 到 9 层。分别为
Conv+Conv+C2f;Conv+C2f;Conv+C2f;Conv+C2f+SPPF;
Conv层使用步长为 2、填充为 1 的 3×3 卷积核进行空间下采样,每次卷积使图像宽高减半,通道数翻倍。根据不同的尺寸的模型,通道数量有所不同,会乘系数w和r。例如对于 YOLOv8s 尺寸的模型,查表可知其w为 0.5,r为2.0,因此其第 3 层卷积层输出的通道数量为 ,而对于第 7 层卷积层输出的通道数量为 。
- 第 4 层
C2f层输出对应特征金字塔 P3 层,适用于小目标的处理; - 第 6 层
C2f层输出对应特征金字塔 P4 层,适用于中等目标的处理; - 第 9 层
SPPF层的输出对应特征金字塔 P5 层,适用于大目标的处理。
这三层的输出特征图将直接传递给 Head 部分的检测头,用于不同尺度下的目标检测任务。
3 Head

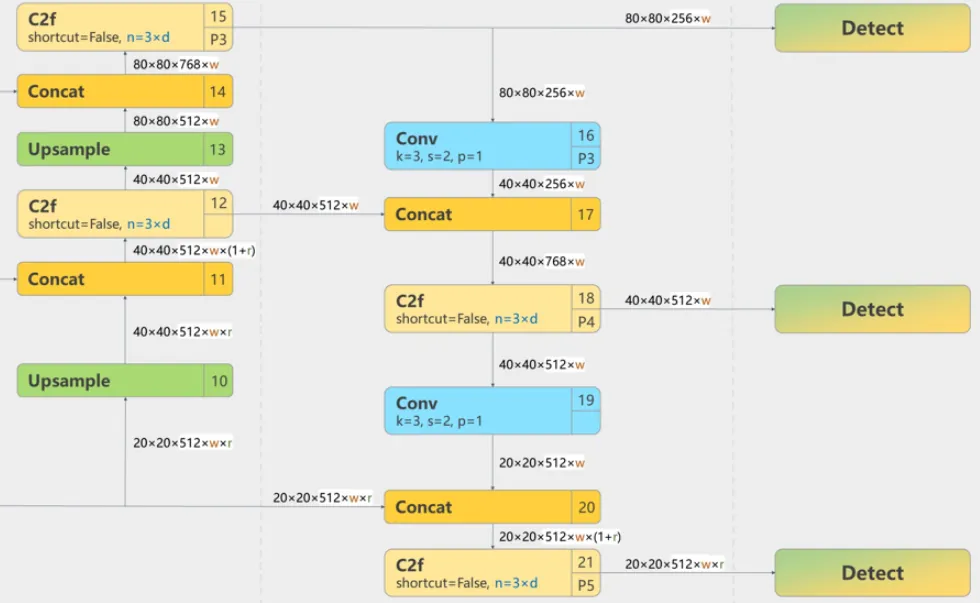
YOLOv8 Head 部分的概览见结构图上部,详细结构在右下部分。
YOLOv8 引入了 PAN-FPN 作为其特征金字塔网络,进一步增强其多尺度特征的表示能力。
PAN 和 FPN
特征金字塔网络(Feature Pyramid Network,FPN)负责构建从底层到高层的多尺度特征图,即第 10 层到 15 层。FPN 从深层特征开始,逐层向上采样。每一层的上采样特征与相应的低层特征进行融合,以补充空间信息、增强语义信息。
路径聚合网络(Path Aggregation Network,PAN)是在 FPN 的基础上,进一步增强特征金字塔网络的结构,即第 16 到 21 层。PAN 从底层特征开始,逐层向上传递特征。每一层的特征图通过自底向上的路径与高层特征图进行融合,确保每一层的特征都包含不同尺度的信息。
在 Backbone 中,第 4 层、第 6 层、第 9 层将特征图输入 Head 中进行处理,我们分别称为:
- L4:来自第 4 层特征图(80×80);
- L6:来自第 6 层特征图(40×40);
- L9:来自第 9 层特征图(20×20)。
L4、L6、L9 的处理在 PAN 中分为三步:
- 上采样 L9
第 10 层将 L9 上采样两倍,得到 L10(40×40);
第 11 层将相同尺寸的 L10 与 L6 融合,得到 L11(40×40)。
- 上采样 L11
L11 经过第 12 层C2f处理后,再上采样两倍,得到 L13(80×80);
第 14 层将相同尺寸的 L13 与 L4 融合,得到 L14(80×80)。
- L14 处理 L14 经过第 15 层
C2f处理后,得到 L15(80×80)。
处理得到的 L15 不经过其他处理,作为大尺寸特征图直接送入 Detect 模块中检测。
然后 L15、L12、L9 将送入 FPN 网络中处理:
- L15 下采样
L15 经过第 16 层卷积层下采样,宽高减半,得到 L16(40×40);
第 17 层将相同尺寸的 L16 和 L12 融合,得到 L17(40×40)。
- L17 下采样
L17 先在第 18 层进行一次C2f处理,得到 L18(40×40),L18 将作为中等尺寸特征图送入 Detect 处理。
L18 经过第 19 层卷积层下采样,宽高减半,得到 L19(20×20)。
- L19 处理
第 20 层将相同尺寸的 L19 和 L9 融合,得到 L20(20×20);
L20 经过第 21 层C2f处理,得到 L21(20×20),L21 将作为小尺寸特征图送入 Detect 处理。
总结,Head 从 Backbone 中接收 L4、L6、L9 三种大、中、小尺寸的特征图,进行 PAN 和 FPN 处理后,得到大、中、小三种尺寸的特征图 L15、L18、L19 分别进行检测。